Una mirada a la transformada rápida de Fourier (FFT)
Usualmente hemos trabajado sobre la intensidad en el tiempo, tanto para hacer síntesis, como para hacer cualquier otro tipo de modificación. Sin embargo, los sonidos pueden ser compuestos por muchas frecuencias en diversas situaciones de intensidad y es precisamente ese dominio, el de las frecuencias y sus intensidades, el que resulta de un gran interés para la entrada de hoy.
Supongamos, como en otro momento hizo Jean-Baptiste Fourier, que una señal cualquiera en el dominio del tiempo puede ser reconstituida como la suma de ondas sinusoidales con diferentes intensidades, frecuencias y fases. Para ello tenemos que tener en cuenta que una representación de cada una de dichas ondas sería: y(t) = A sin (w(t) + x), donde A es la amplitud o intensidad, w(t) es la frecuencia o ángulo dependiente del tiempo y x sería un desplazamiento en el eje horizontal o desplazamiento de fase. Por ejemplo, para tener una señal con un contenido tímbrico armónico deberíamos tener una suma como: y(t) = A sin (w(t) + x) + 1/2A sin (2w(t) + x) + 1/4A sin (3w(t) + x) + ...
Adicional a este pensamiento de la representación, también tenemos que tener en cuenta el dispositivo que procesa el flujo de información y la manera en la cual lo hace. Para nuestro caso, en Pure Data, vamos a tomar pequeños fragmentos de sonido, pues a la larga determinar la suma componentes en un fragmento pequeño, va a resultar mucho más sencillo que intentar hacerlo para un gran trozo de sonido, o por lo menos resulta más representativo hacerlo así.
La tasa de muestreo o el tamaño del sonido que vamos a usar, es manipulado a través del objeto block~, que toma como parámetros de inicialización el tamaño del bloque, que debe ser 2^n, la cantidad de bloques a ser superpuestos y un factor para remuestrear (downsampling/upsampling),
por ahora, sólo usaremos los dos primeros.
Comencemos por usar un tamaño de bloque de 1024 muestras y 4 bloques. Al superponer esos bloques vamos a necesitar también agregarles una envolvente para que no se sienta la discontinuidad que puede generarse al tomar pequeños fragmentos. Para tal propósito usaremos el objeto bwin~, el cual toma como parámetro de inicio un nombre de forma para la envolvente, en este caso hamming (Leer esto para información sobre ventanas).
Luego, la señal que tenemos va a ingresar al objeto de análisis que usa la transformada rápida de Fourier: rfft~, que para simplificar un poco, va a ser la identificación de la situación de amplitud, frecuencia y fase del sonido entrante. En este caso, lo que hará será dividir la señal en "contenedores de información" (en inglés: bins, ver acá más información sobre las informaciones que se generan) que responden a la división de la tasa de muestreo por el tamaño de bloque que usemos. Como escogimos 1024, la operación es 44100/1024 = 43,0664Hz, es decir, cada contenedor tiene ese tamaño y será representativo de ese rango de frecuencias. (Leer nota al final)
Como bien sabemos, la máxima representación de frecuencia es la mitad de la tasa de muestreo, lo que quiere decir que de esos 1024 contenedores, sólo vamos a tener información útil en los primeros 512 componentes (1024 / 2), esa es la razón por la cual al pasar un sonido cualquiera a través del objeto rfft~ vamos a tener tamaño-de-bloque/2 datos y tamaño-de-bloque/2 ceros. Es importante, o por lo menos lo es para mí, entender este proceso, porque poder manipular esa información es lo que nos va a permitir crear unas muy interesantes gamas de sonidos, es justo después de haber obtenido esta información que se puede intervenir fuertemente y con un detalle muy interesante una señal entrante. Por ejemplo, supongamos que queremos cambiar la intensidad de cada uno de esos componentes individualmente, o que queremos identificar cuales son los componentes de ese sonido entrante que son menores a un umbral específico, o que un rango particular de intensidades en un sonido nos resultan llamativas y que deseamos separarlas del resto, sea para modularlas, para distorsionarlas, para retrasarlas, etc., las posibilidades son realmente muchas.
Implementemos un filtro, continuando con lo que hemos visto hasta acá. Como tenemos contenedores de información de 43,06..Hz aproximadamente, estos funcionarán como un filtro pasa-banda que no tiene decaimiento antes o después de sus frecuencias de corte. Lo único que necesitamos es manipular la información de los contenedores individualmente. Para tal propósito es necesaria una tabla con 512 posiciones y un objeto que permita procesar la tabla de la misma manera que estamos haciendo con la señal entrante, es decir, que permita procesar por bloques, por lo cual usaremos tabreceive~.
Los valores que usaremos en la tabla serán entre 0 y 1, pensemos en ellos como "faders" y por tanto el tipo de proceso o la función que tienen respecto al parámetro que van a manipular. Como lo que haremos es cambiar las intensidades de diversas frecuencias que tenga cualquier señal entrante, necesitamos que el comportamiento de cada "fader" sea exponencial elevando al cuadrado para este ejemplo, lo que salga de tabreceive~.
A su vez, multiplicaremos lo que acabamos de obtener con lo que se obtiene de rfft~ para obtener el comportamiento de filtrado que se consigne en la tabla. Seguido a esto, se envía el sonido a un objeto de resíntesis, o sea, el proceso contrario a descomponer la señal, ahora lo reintegraremos modificado usando el objeto rifft~, seguido de una normalización de la intensidad, pues en el paso por fft y la superposición se ha dado una ganancia adicional.
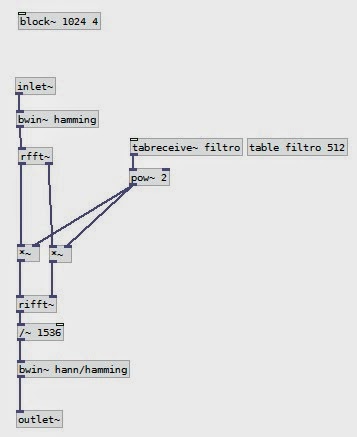 El siguiente paso es conectar a este subpatch o abstracción una señal y comenzar a cambiar los valores de la tabla "filtro".
El siguiente paso es conectar a este subpatch o abstracción una señal y comenzar a cambiar los valores de la tabla "filtro".
Ahora, con 512 filtros, que tienen una distribución lineal, tal vez sea muy apropiado manipular con un alto detalle las frecuencias altas y con mucho menor detalle las frecuencias más graves.
Nota al final
El problema del detalle puede ser tratado con bloques más grandes, pero eso implica también que si los bloques son muy grandes se hace notorio un retraso en el procesamiento.
Cada milisegundo a 44100 son 44.1 muestras, lo que quiere decir que si tenemos un bloque de 1024 el tiempo por bloque es cercano a 23 milisegundos para hacer el proceso, lo cual alcanza a estar por debajo del umbral de percepción, pero también es un porcentaje de tiempo significativo en materiales musicales rápidos.
Dependiendo de la cantidad de detalle y el uso que se le vaya a dar al sonido que se procesa es posible cambiar los tamaños de tablas y bloques, así que, previo al uso, vale la pena pensar en la naturaleza de la señal.
Supongamos, como en otro momento hizo Jean-Baptiste Fourier, que una señal cualquiera en el dominio del tiempo puede ser reconstituida como la suma de ondas sinusoidales con diferentes intensidades, frecuencias y fases. Para ello tenemos que tener en cuenta que una representación de cada una de dichas ondas sería: y(t) = A sin (w(t) + x), donde A es la amplitud o intensidad, w(t) es la frecuencia o ángulo dependiente del tiempo y x sería un desplazamiento en el eje horizontal o desplazamiento de fase. Por ejemplo, para tener una señal con un contenido tímbrico armónico deberíamos tener una suma como: y(t) = A sin (w(t) + x) + 1/2A sin (2w(t) + x) + 1/4A sin (3w(t) + x) + ...
Adicional a este pensamiento de la representación, también tenemos que tener en cuenta el dispositivo que procesa el flujo de información y la manera en la cual lo hace. Para nuestro caso, en Pure Data, vamos a tomar pequeños fragmentos de sonido, pues a la larga determinar la suma componentes en un fragmento pequeño, va a resultar mucho más sencillo que intentar hacerlo para un gran trozo de sonido, o por lo menos resulta más representativo hacerlo así.
La tasa de muestreo o el tamaño del sonido que vamos a usar, es manipulado a través del objeto block~, que toma como parámetros de inicialización el tamaño del bloque, que debe ser 2^n, la cantidad de bloques a ser superpuestos y un factor para remuestrear (downsampling/upsampling),
por ahora, sólo usaremos los dos primeros.
Comencemos por usar un tamaño de bloque de 1024 muestras y 4 bloques. Al superponer esos bloques vamos a necesitar también agregarles una envolvente para que no se sienta la discontinuidad que puede generarse al tomar pequeños fragmentos. Para tal propósito usaremos el objeto bwin~, el cual toma como parámetro de inicio un nombre de forma para la envolvente, en este caso hamming (Leer esto para información sobre ventanas).
Luego, la señal que tenemos va a ingresar al objeto de análisis que usa la transformada rápida de Fourier: rfft~, que para simplificar un poco, va a ser la identificación de la situación de amplitud, frecuencia y fase del sonido entrante. En este caso, lo que hará será dividir la señal en "contenedores de información" (en inglés: bins, ver acá más información sobre las informaciones que se generan) que responden a la división de la tasa de muestreo por el tamaño de bloque que usemos. Como escogimos 1024, la operación es 44100/1024 = 43,0664Hz, es decir, cada contenedor tiene ese tamaño y será representativo de ese rango de frecuencias. (Leer nota al final)
Como bien sabemos, la máxima representación de frecuencia es la mitad de la tasa de muestreo, lo que quiere decir que de esos 1024 contenedores, sólo vamos a tener información útil en los primeros 512 componentes (1024 / 2), esa es la razón por la cual al pasar un sonido cualquiera a través del objeto rfft~ vamos a tener tamaño-de-bloque/2 datos y tamaño-de-bloque/2 ceros. Es importante, o por lo menos lo es para mí, entender este proceso, porque poder manipular esa información es lo que nos va a permitir crear unas muy interesantes gamas de sonidos, es justo después de haber obtenido esta información que se puede intervenir fuertemente y con un detalle muy interesante una señal entrante. Por ejemplo, supongamos que queremos cambiar la intensidad de cada uno de esos componentes individualmente, o que queremos identificar cuales son los componentes de ese sonido entrante que son menores a un umbral específico, o que un rango particular de intensidades en un sonido nos resultan llamativas y que deseamos separarlas del resto, sea para modularlas, para distorsionarlas, para retrasarlas, etc., las posibilidades son realmente muchas.
Implementemos un filtro, continuando con lo que hemos visto hasta acá. Como tenemos contenedores de información de 43,06..Hz aproximadamente, estos funcionarán como un filtro pasa-banda que no tiene decaimiento antes o después de sus frecuencias de corte. Lo único que necesitamos es manipular la información de los contenedores individualmente. Para tal propósito es necesaria una tabla con 512 posiciones y un objeto que permita procesar la tabla de la misma manera que estamos haciendo con la señal entrante, es decir, que permita procesar por bloques, por lo cual usaremos tabreceive~.
Los valores que usaremos en la tabla serán entre 0 y 1, pensemos en ellos como "faders" y por tanto el tipo de proceso o la función que tienen respecto al parámetro que van a manipular. Como lo que haremos es cambiar las intensidades de diversas frecuencias que tenga cualquier señal entrante, necesitamos que el comportamiento de cada "fader" sea exponencial elevando al cuadrado para este ejemplo, lo que salga de tabreceive~.
A su vez, multiplicaremos lo que acabamos de obtener con lo que se obtiene de rfft~ para obtener el comportamiento de filtrado que se consigne en la tabla. Seguido a esto, se envía el sonido a un objeto de resíntesis, o sea, el proceso contrario a descomponer la señal, ahora lo reintegraremos modificado usando el objeto rifft~, seguido de una normalización de la intensidad, pues en el paso por fft y la superposición se ha dado una ganancia adicional.
Ahora, con 512 filtros, que tienen una distribución lineal, tal vez sea muy apropiado manipular con un alto detalle las frecuencias altas y con mucho menor detalle las frecuencias más graves.
Nota al final
El problema del detalle puede ser tratado con bloques más grandes, pero eso implica también que si los bloques son muy grandes se hace notorio un retraso en el procesamiento.
Cada milisegundo a 44100 son 44.1 muestras, lo que quiere decir que si tenemos un bloque de 1024 el tiempo por bloque es cercano a 23 milisegundos para hacer el proceso, lo cual alcanza a estar por debajo del umbral de percepción, pero también es un porcentaje de tiempo significativo en materiales musicales rápidos.
Dependiendo de la cantidad de detalle y el uso que se le vaya a dar al sonido que se procesa es posible cambiar los tamaños de tablas y bloques, así que, previo al uso, vale la pena pensar en la naturaleza de la señal.


gracias por el aporte... me pregunto si para fines de solo análisis el bloque que se necesita mas grande, que valores puede tener?
ResponderEliminarPara analizar vale la pena tener tamaños de bloque que permitan obtener detalle. Claro que también dependerá del sonido, por ejemplo, si es el análisis de algo agudo no es tan problemático, pero si es para detección de fundamentales en el registro grave, se necesita un tamaño de bloque más grande. En Pure Data son potencias de dos (2^n), 1024 (43hz por contenedor), 2048 (21Hz por contenedor), 4096 (10,7Hz por contenedor) y así sucesivamente.
EliminarPara analizar vale la pena tener tamaños de bloque que permitan obtener detalle. Claro que también dependerá del sonido, por ejemplo, si es el análisis de algo agudo no es tan problemático, pero si es para detección de fundamentales en el registro grave, se necesita un tamaño de bloque más grande. En Pure Data son potencias de dos (2^n), 1024 (43hz por contenedor), 2048 (21Hz por contenedor), 4096 (10,7Hz por contenedor) y así sucesivamente.
Eliminar